原文链接:
虽然使用缓存思想似乎是一个很简单的事情,但是缓存机制却有一个核心的难点,就是——缓存清理。我们所说的缓存,都是保存一些数据,但是这些数据往往是会变化的,我们要针对这些变化,清理掉保存的“脏”数据,却可能不是那么容易。
首先我们来看看最简单的缓存数据——静态数据。这种数据往往在程序的运行时是不会变化的,比如Web服务器内存中缓存的HTML文件数据,就是这种。事实上,所有的不是由外部用户上传的数据,都属于这种“运行时静态数据”。一般来说,我们对这种数据,可以采用两种建立缓存的方法:一是程序一启动,就一股脑把所有的静态数据从文件或者数据库读入内存;二就是程序启动的时候并不加载静态数据,而是等有用户访问相关数据的时候,才去加载,这也就是所谓lazy load的做法。第一种方法编程比较简单,程序的内存启动后就稳定了,不太容易出现内存漏洞(如果加载的缓存太多,程序在启动后立刻会因内存不足而退出,比较容易发现问题);第二种方法程序启动很快,但要对缓存占用的空间有所限制或者规划,否则如果要缓存的数据太多,可能会耗尽内存,导致在线服务中断。
一般来说,静态数据是不会“脏”的,因为没有用户会去写缓存中的数据。但是在实际工作中,我们的在线服务往往会需要“立刻”变更一些缓存数据。比如在门户网站上发布了一条新闻,我们会希望立刻让所有访问的用户都看到。按最简单的做法,我们一般只要重启一下服务器进程,内存中的缓存就会消失了。对于静态缓存的变化频率非常低的业务,这样是可以的,但是如果是新闻网站,就不能每隔几分钟就重启一下WEB服务器进程,这样会影响大量在线用户的访问。常见的解决这类问题有两种处理策略:
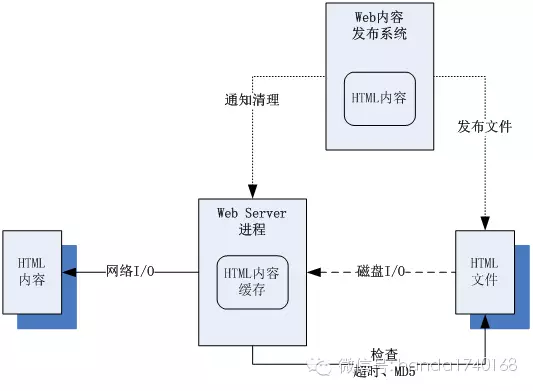
第一种是使用控制命令。简单来说,就是在服务器进程上,开通一个实时的命令端口,我们可以通过网络数据包(如UDP包),或者Linux系统信号(如kill SIGUSR2进程号)之类的手段,发送一个命令消息给服务器进程,让进程开始清理缓存。这种清理可能执行的是最简单的“全部清理”,也有的可以细致一点的,让命令消息中带有“想清理的数据ID”这样的信息,比如我们发送给WEB服务器的清理消息网络包中会带一个字符串URL,表示要清理哪一个HTML文件的缓存。这种做法的好处是清理的操作很精准,可以明确的控制清理的时间和数据。但是缺点就是比较繁琐,手工去编写发送这种命令很烦人,所以一般我们会把清理缓存命令的工作,编写到上传静态数据的工具当中,比如结合到网站的内容发布系统中,一旦编辑提交了一篇新的新闻,发布系统的程序就自动的发送一个清理消息给WEB服务器。
第二种是使用字段判断逻辑。也就是服务器进程,会在每次读取缓存前,根据一些特征数据,快速的判断内存中的缓存和源数据内容,是否有不一致(是否脏)的地方,如果有不一致的地方,就自动清理这条数据的缓存。这种做法会消耗一部分CPU,但是就不需要人工去处理清理缓存的事情,自动化程度很高。现在我们的浏览器和WEB服务器之间,就有用这种机制:检查文件MD5;或者检查文件最后更新时间。具体的做法,就是每次浏览器发起对WEB服务器的请求时,除了发送URL给服务器外,还会发送一个缓存了此URL对应的文件内容的MD5校验串、或者是此文件在服务器上的“最后更新时间”(这个校验串和“最后更新时间”是第一次获的文件时一并从服务器获得的);服务器收到之后,就会把MD5校验串或者最后更新时间,和磁盘上的目标文件进行对比,如果是一致的,说明这个文件没有被修改过(缓存不是“脏”的),可以直接使用缓存。否则就会读取目标文件返回新的内容给浏览器。这种做法对于服务器性能是有一定消耗的,所以如果往往我们还会搭配其他的缓存清理机制来用,比如我们会在设置一个“超时检查”的机制:就是对于所有的缓存清理检查,我们都简单的看看缓存存在的时间是否“超时”了,如果超过了,才进行下一步的检查,这样就不用每次请求都去算MD5或者看最后更新时间了。但是这样就存在“超时”时间内缓存变脏的可能性。
上面说了运行时静态的缓存清理,现在说说运行时变化的缓存数据。在服务器程序运行期间,如果用户和服务器之间的交互,导致了缓存的数据产生了变化,就是所谓“运行时变化缓存”。比如我们玩网络游戏,登录之后的角色数据就会从数据库里读出来,进入服务器的缓存(可能是堆内存或者memcached、共享内存),在我们不断进行游戏操作的时候,对应的角色数据就会产生修改的操作,这种缓存数据就是“运行时变化的缓存”。这种运行时变化的数据,有读和写两个方面的清理问题:由于缓存的数据会变化,如果另外一个进程从数据库读你的角色数据,就会发现和当前游戏里的数据不一致;如果服务器进程突然结束了,你在游戏里升级,或者捡道具的数据可能会从内存缓存中消失,导致你白忙活了半天,这就是没有回写(缓存写操作的清理)导致的问题。这种情况在电子商务领域也很常见,最典型的就是火车票网上购买的系统,火车票数据缓存在内存必须有合适的清理机制,否则让两个买了同一张票就麻烦了,但如果不缓存,大量用户同时抢票,服务器也应对不过来。因此在运行时变化的数据缓存,应该有一些特别的缓存清理策略。
在实际运行业务中,运行变化的数据往往是根据使用用户的增多而增多的,因此首先要考虑的问题,就是缓存空间不够的可能性。我们不太可能把全部数据都放到缓存的空间里,也不可能清理缓存的时候就全部数据一起清理,所以我们一般要对数据进行分割,这种分割的策略常见的有两种:一种是按重要级来分割,一种是按使用部分分割。
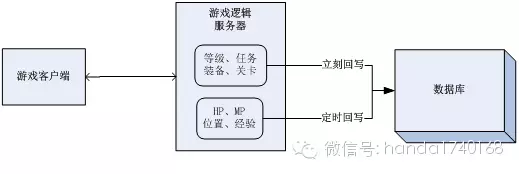
先举例说说“按重要级分割”,在网络游戏中,同样是角色的数据,有些数据的变化可能会每次修改都立刻回写到数据库(清理写缓存),其他一些数据的变化会延迟一段时间,甚至有些数据直到角色退出游戏才回写,如玩家的等级变化(升级了),武器装备的获得和消耗,这些玩家非常看重的数据,基本上会立刻回写,这些就是所谓最重要的缓存数据。而玩家的经验值变化、当前HP、MP的变化,就会延迟一段时间才写,因为就算丢失了缓存,玩家也不会太过关注。最后有些比如玩家在房间(地区)里的X/Y坐标,对话聊天的记录,可能会退出时回写,甚至不回写。这个例子说的是“写缓存”的清理,下面说说“读缓存”的按重要级分割清理。
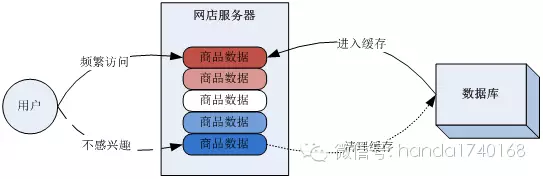
假如我们写一个网店系统,里面容纳了很多产品,这些产品有一些会被用户频繁检索到,比较热销,而另外一些商品则没那么热销。热销的商品的余额、销量、评价都会比较频繁的变化,而滞销的商品则变化很少。所以我们在设计的时候,就应该按照不同商品的访问频繁程度,来决定缓存哪些商品的数据。我们在设计缓存的结构时,就应该构建一个可以统计缓存读写次数的指标,如果有些数据的读写频率过低,或者空闲(没有人读、写缓存)时间超长,缓存应该主动清理掉这些数据,以便其他新的数据能进入缓存。这种策略也叫做“冷热交换”策略。实现“冷热交换”的策略时,关键是要定义一个合理的冷热统计算法。一些固定的指标和算法,往往并不能很好的应对不同硬件、不同网络情况下的变化,所以现在人们普遍会用一些动态的算法,如Redis就采用了5种,他们是:
1.根据过期时间,清理最长时间没用过的
2.根据过期时间,清理即将过期的
3.根据过期时间,任意清理一个
4. 无论是否过期,随机清理
5.无论是否过期,根据LRU原则清理:所谓LRU,就是Least Recently Used,最近最久未使用过。这个原则的思想是:如果一个数据在最近一段时间没有被访问到,那么在将来他被访问的可能性也很小。LRU是在操作系统中很常见的一种原则,比如内存的页面置换算法(也包括FIFO,LFU等),对于LRU的实现,还是非常有技巧的,但是本文就不详细去说明如何实现,留待大家上网搜索“LRU”关键字学习。
数据缓存的清理策略其实远不止上面所说的这些,要用好缓存这个武器,就要仔细研究需要缓存的数据特征,他们的读写分布,数据之中的差别。然后最大化的利用业务领域的知识,来设计最合理的缓存清理策略。这个世界上不存在万能的优化缓存清理策略,只存在针对业务领域最优化的策略,这需要我们程序员深入理解业务领域,去发现数据背后的规律。